П口чему нейр口сети делают так: история иероглифа в русском тексте
Сидишь, гоняешь LLM модельку, просишь её написать что-то осмысленное про погоду в Воронеже. Она бодро выдаёт: «Сегодня в Воронеже 你ожидается переменная облачность». Стоп. Откуда «你»? Ты не китаист, модель не китаист, в промпте никаких иероглифов не было. А оно есть.
Если такое хоть раз ловили – в Llama, в Mistral, в каком-нибудь Qwen, да даже в больших облачных моделях иногда проскакивает (хотя в GPT5 и Gemini 3 моделях все реже) – вопрос «почему так» застревает в голове надолго. И честный ответ на него нельзя дать в одну строчку «потому что баг». Это не баг. Это прямое следствие того, как модель устроена внутри. И когда понимаешь устройство, иероглиф перестаёт быть мистикой и становится логичным следствием.
Статья разделена на два уровня. Первый – для тех, кто слово «эмбеддинг» слышал, но руками не трогал: разберём на пальцах, что лежит внутри цифрового серого вещества модели. Второй – для тех, кому хочется копнуть глубже: туда положены grokking, фурье-частоты, суперпозиция и реальная геометрия пространства обученной модели.
Поехали.
Часть 1. База: что вообще такое «думает» нейросеть
Текст, которого модель не видит
Первое, что нужно принять: модель не видит текст. Совсем. Никаких букв «к», «о», «т» она не получает. Когда вы пишете «кот сидит на окне», на вход уходят числа.
Превращение текста в числа называется токенизацией (нарезка текста на куски-токены, где токен – это слово, часть слова, символ или последовательность байтов). У каждой модели свой словарь токенов. У GPT-подобных моделей он обычно содержит 30 000 – 200 000 токенов. У Llama – около 32 000 в старых версиях, 128 000 в свежих. У Qwen – больше, потому что туда впихнули много китайского.
Слово «кот» может стать одним токеном с номером, например, 12 843. Слово «котяра» – уже двумя: «кот» + «яра». А слово «непротивоконституционализм» развалится на десяток кусков.
Окей, текст превратился в список чисел. Дальше что?
Эмбеддинг: каждому токену – свой адрес в пространстве
Дальше начинается самое интересное. Каждый номер токена превращается в эмбеддинг (вектор – длинный список чисел, обычно от 768 до 12 288 штук). Этот вектор – «адрес» токена в многомерном пространстве смыслов.
Звучит абстрактно, поэтому давайте на пальцах.
Представьте обычную двумерную карту. У каждого города две координаты: широта и долгота. Москва – одна точка, Питер – другая, Воронеж – третья. По расстоянию между точками можно судить, насколько города близки.
Теперь представьте, что вместо двух координат у нас 4096. И вместо городов – слова. «Кот» – точка в этом пространстве. «Кошка» – другая точка, очень близкая к «коту». «Собака» – тоже недалеко, потому что тоже домашнее животное. «Самосвал» – где-то далеко.
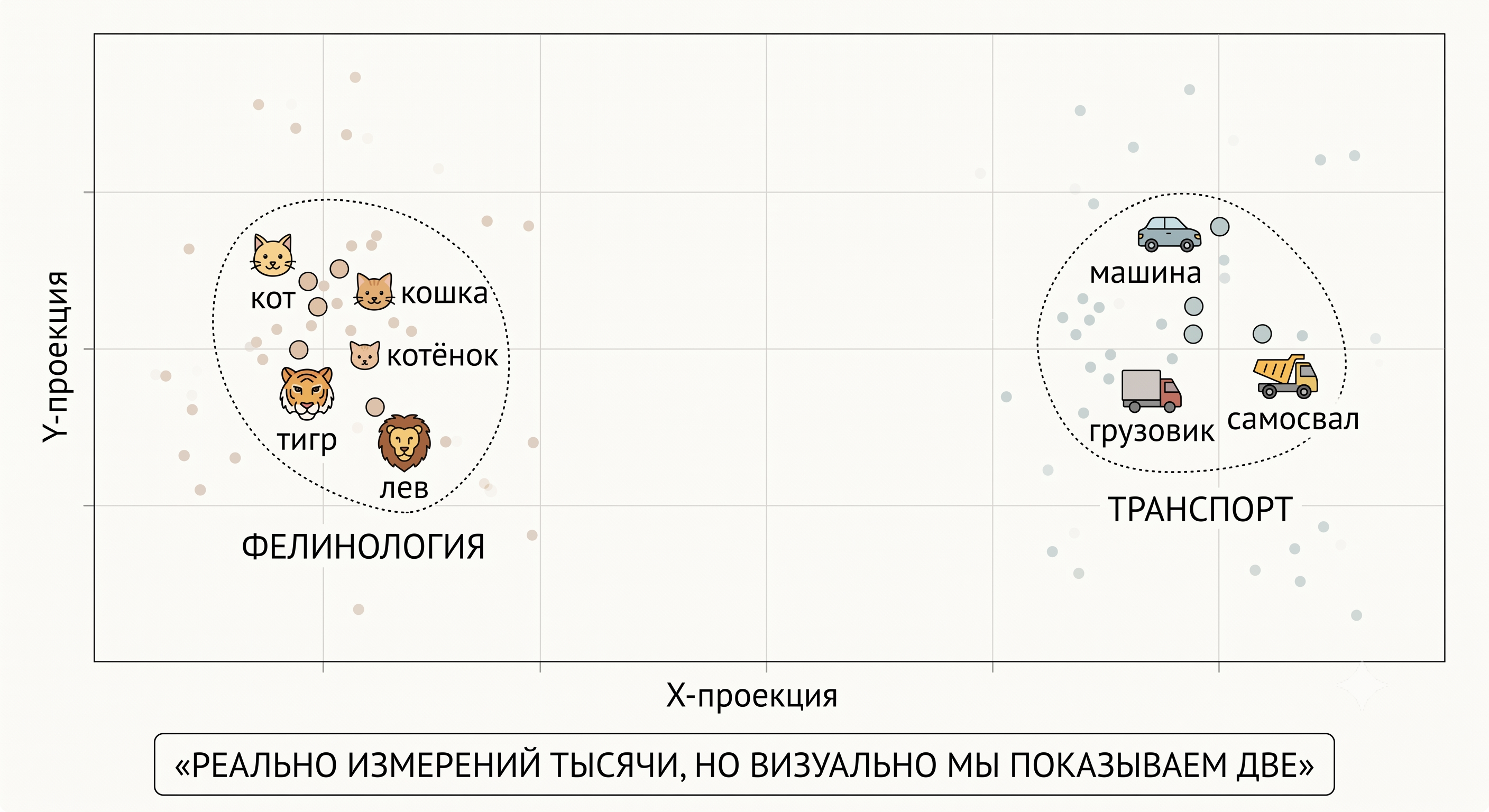
Эта геометрия не случайная. Модель её выучила на огромных объёмах текстов. Если в текстах «кот» и «кошка» встречаются в похожих контекстах, модель сдвигает их векторы ближе. Если «кот» и «самосвал» – почти никогда, они расходятся.
Знаменитый пример: вектор(«король») − вектор(«мужчина») + вектор(«женщина») ≈ вектор(«королева»). Арифметика на смыслах работает, потому что модель уложила слова в пространстве с понятной геометрией.
Слой за слоем: как из адресов получается смысл
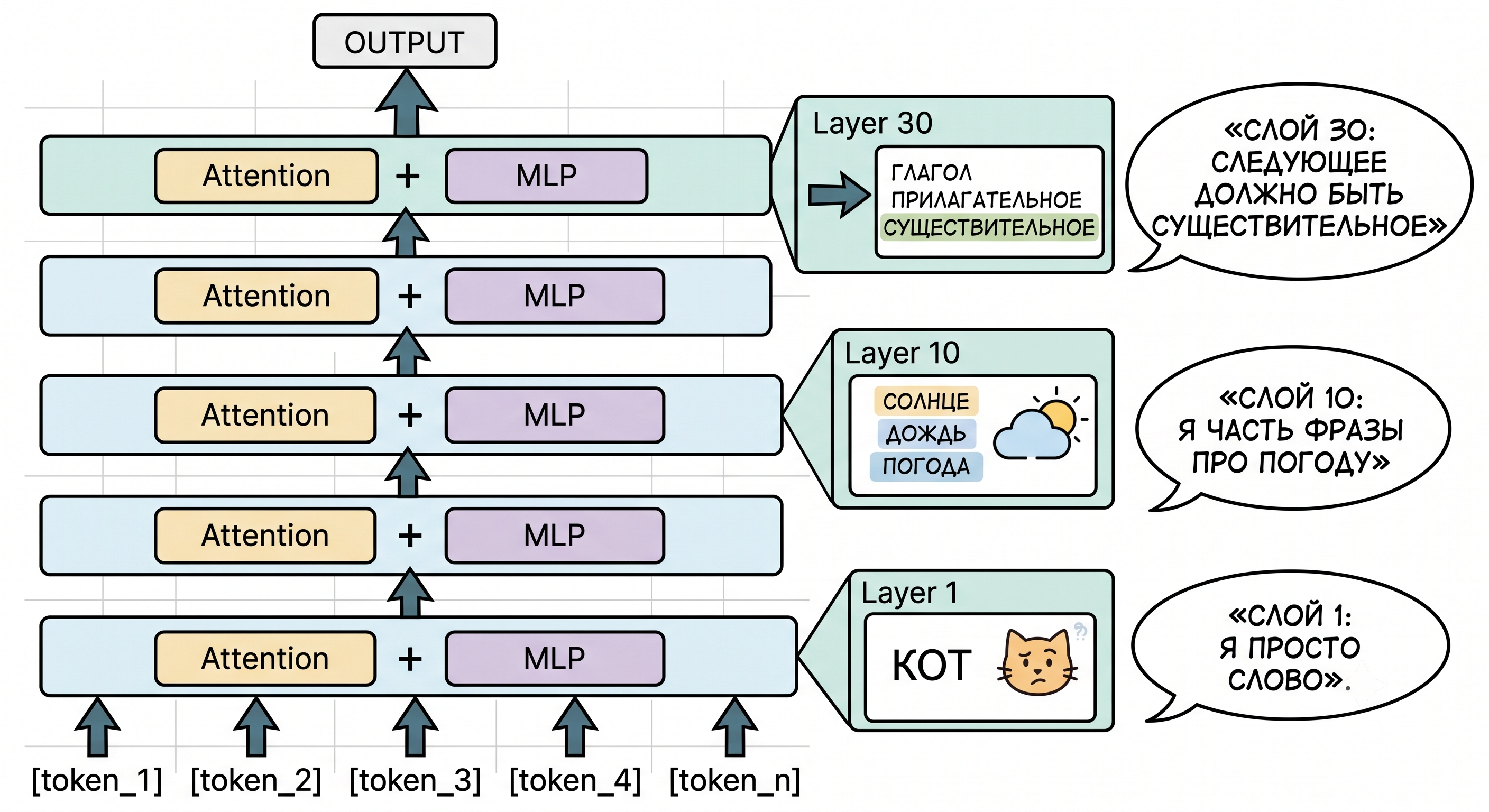
Эмбеддинги – это только вход. Дальше начинаются слои трансформера (повторяющиеся блоки внутри модели, которые перемешивают и преобразуют векторы). В GPT-3 их 96. В Llama 3 70B – 80. В маленькой локальной модели может быть 32.
Каждый слой делает примерно одно и то же:
Смотрит на все токены сразу через механизм внимания (attention – способ для каждого токена «оглянуться» на остальные и понять, кто из них важен в данный момент).
Перемешивает информацию между токенами.
Прогоняет каждый вектор через небольшую обычную нейросеть (MLP – multi-layer perceptron, многослойный перцептрон).
Передаёт результат на следующий слой.
К концу всех слоёв у каждого токена в его векторе записано уже не «я слово кот», а «я слово кот, в контексте про погоду, я тут не главный, главный – глагол сидит, и дальше должен идти предлог». Вся эта информация – просто числа в длинном векторе.
Финальный шаг: как из вектора получается следующее слово
После последнего слоя у нас есть итоговый вектор. Это «состояние модели после прочтения всего, что было». Чтобы предсказать следующий токен, модель делает финальный трюк: умножает этот вектор на огромную матрицу размером «размер словаря × размер вектора».
На выходе получается список чисел длиной во весь словарь. Каждое число – «насколько модель считает, что следующий токен – именно этот».
Этот список прогоняется через softmax (функция, которая превращает любые числа в вероятности, сумма которых равна 1). И получаются проценты: «кот» – 0.3%, «собака» – 8%, «лежит» – 23%, «сидит» – 41%, и так далее по всем 128 000 токенам словаря.
Дальше модель выбирает один токен. И вот тут начинается история иероглифа.
Сэмплинг: рулетка, которая решает всё
Если бы модель всегда брала самый вероятный токен, тексты были бы скучные и зацикленные. Поэтому существует сэмплинг (процесс случайного выбора токена с учётом вероятностей).
Главные параметры:
Температура – чем выше, тем сильнее «размазываются» вероятности. При температуре 0 берётся всегда самый вероятный токен. При температуре 1 распределение остаётся как есть. При температуре 2 разница между «сидит» с 41% и «你» с 0.001% сильно уменьшается.
top-k – оставляем только k самых вероятных токенов, остальные отбрасываем.
top-p (nucleus) – оставляем минимальный набор токенов, чья суммарная вероятность ≥ p.
Когда вы запускаете локальную модель, у неё часто стоят дефолтные настройки: температура 0.8, top-p 0.95. На вид безопасно. Но если в распределении есть длинный хвост из 50 000 токенов с микроскопическими вероятностями, top-p 0.95 может зацепить и их. И один раз из тысячи рулетка остановится на «你».
Это уже половина ответа на вопрос из заголовка. Но только половина. Потому что остаётся вопрос: почему вообще «你» оказался в распределении с ненулевой вероятностью? Откуда он там, если речь о погоде в Воронеже?
И вот тут переходим ко второй части.
Часть 2. Глубже: суперпозиция, фурье-частоты и геометрия пространства
Сколько концептов влезает в один вектор
Возьмём вектор размером 4096. Сколько разных «смыслов» модель может в нём закодировать?
Наивный ответ: 4096. По одной координате на каждый смысл. Это называется базисной кодировкой: каждая ось пространства = один концепт.
Но модели так не делают. Им нужно закодировать миллионы концептов: «кот», «грусть», «французская революция», «формула воды», «глагол прошедшего времени», «нота ля». 4096 осей – мало.
И тут вступает суперпозиция (явление, когда несколько концептов кодируются одним и тем же набором координат, накладываясь друг на друга). Эту штуку откопали ребята из Anthropic в своих исследованиях по интерпретируемости.
Идея такая: если концепты редко встречаются вместе, их можно «склеить» в одном направлении пространства. Модель полагает, что «кот» и «вторая мировая война» одновременно почти никогда не активны, и засовывает их в перекрывающиеся векторы. В нужный момент по контексту разделит.
Это даёт модели огромную вместимость. Но за это есть плата.
Цена суперпозиции: интерференция и галлюцинации
Когда два концепта живут в перекрывающихся направлениях, при активации одного немножко активируется и другой. Это называется интерференция (помеха, наводка одного сигнала на другой).
Если «кот» и «你» (китайский «ты») в пространстве модели оказались близко – а такое легко могло случиться при обучении, если они оба часто попадали в начало фразы или после похожих служебных слов – то при генерации текста про кота вектор «你» получает крошечную, но ненулевую активацию.
При температуре 0 это ничем не грозит: «сидит» выиграет с 41%. Но при сэмплинге с хвостом – привет, иероглиф.
Это и есть прямой ответ на вопрос из заголовка. Нейросеть выдаёт иероглиф в русском тексте, потому что её внутреннее пространство устроено через суперпозицию, и редкие токены живут на «спинах» частых, наводя слабый сигнал даже там, где их не ждали.
Grokking: модель сначала зубрит, потом понимает
Здесь полезно вспомнить о явлении grokking (его можно перевести как «прозрение» или «внезапное понимание»). Это момент, когда нейросеть после долгого периода застоя внезапно начинает обобщать знания, а не просто запоминать их. Впервые это заметили на небольших моделях, которые обучали арифметике по модулю (например, вычислению остатка от деления).
Процесс происходит в два этапа:
Фаза заучивания. Сначала модель просто «зубрит» примеры. Ошибка (loss) на обучающих данных снижается, но на проверочных (валидации) остаётся высокой. Модель может прогнать тысячи эпох, так и не научившись решать новые, незнакомые задачи.
Фазовый переход. Внезапно модель находит скрытую внутреннюю закономерность, которая позволяет ей решать задачу по-настоящему. Ошибка на проверочных данных резко падает. В этот момент можно сказать, что модель наконец «поняла» принцип, а не просто выучила ответы.
Что важно: когда исследователи открыли капот grokked-модели, обученной на сложении по модулю, они обнаружили внутри... дискретное преобразование Фурье. Модель самопроизвольно научилась раскладывать числа в синусы и косинусы, чтобы делать модульную арифметику.
Кратко о Дискретном преобразовании Фурье (ДПФ) опуская огромное количество тонкостей:
Это математический алгоритм, который раскладывает сложный цифровой сигнал (например, звук, изображение или любой набор данных) на простые составляющие — синусоидальные волны разных частот.
Это как призма, которая раскладывает белый свет на радугу, или как экран музыкального эквалайзера, который показывает, сколько в треке басов, средних и высоких частот.
Зачем это нужно:
ДПФ переводит данные из временной области (как сигнал меняется момент за моментом) в частотную (из каких частот этот сигнал состоит и насколько они сильные).
Именно на этом принципе работают сжатие аудио (MP3) и изображений (JPEG), шумоподавление в наушниках, МРТ-сканеры и анализ финансовых графиков.
То есть модель нашла самую компактную, самую красивую математическую структуру для задачи. Сама. Никто её этому не учил.
Зачем нам Фурье в разговоре про иероглифы
Затем, что это та же история, только в большом масштабе. Когда большая языковая модель обучается на терабайтах текста, она тоже находит самые экономные способы хранить информацию. И эти способы часто оказываются геометрическими и периодическими.
Например, концепты «дни недели» в обученных моделях лежат на окружности. «Январь, февраль, март...» – тоже на окружности. Числительные – на спирали. Это не запрограммировано. Это вылезло само, потому что так компактнее.
А раз структура геометрическая и периодическая, то у неё есть частоты. И эти частоты могут резонировать с совершенно неожиданными вещами. Условно говоря, токен китайского иероглифа и токен русского предлога могут оказаться на одной «гармонике» – не потому что они похожи по смыслу, а потому что модели было экономнее уложить их рядом.
Как достать пространство модели и посмотреть
Это можно сделать руками. Берёте любую open-source модель (Llama, Mistral, Qwen, что угодно), вытаскиваете её embedding-матрицу – это просто большой тензор размером [размер_словаря × размер_вектора].
import torch
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained("какая-нибудь-модель")
tokenizer = AutoTokenizer.from_pretrained("какая-нибудь-модель")
embeddings = model.get_input_embeddings().weight.detach()
# embeddings.shape = [vocab_size, hidden_dim]
Дальше можно прогнать через PCA или t-SNE (методы понижения размерности для визуализации), и посмотреть глазами.
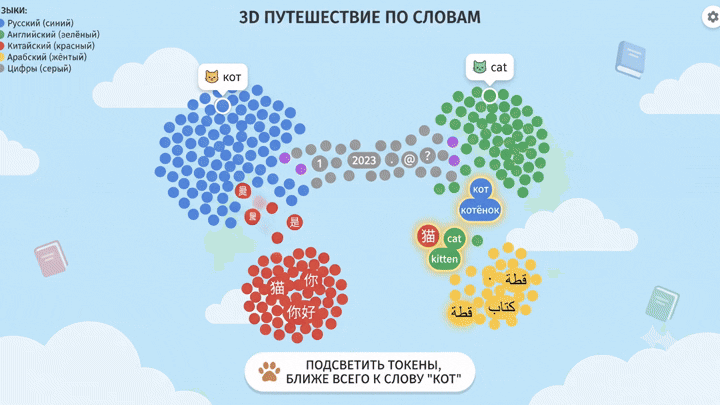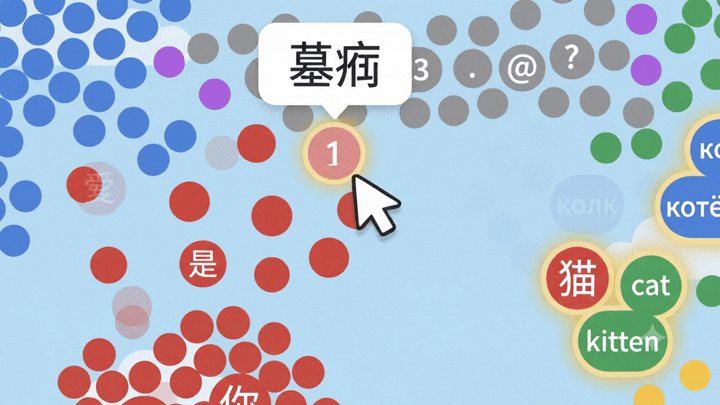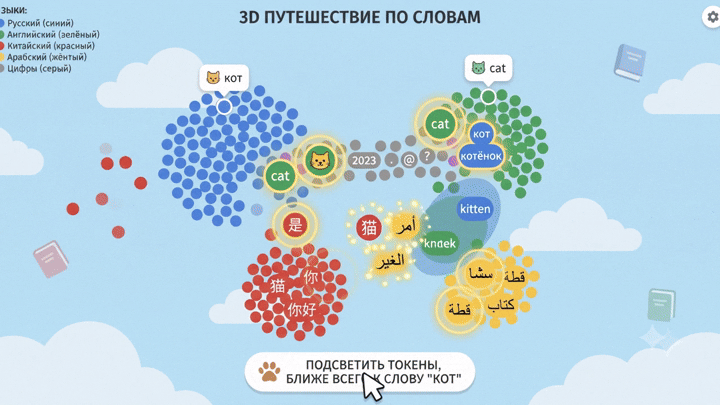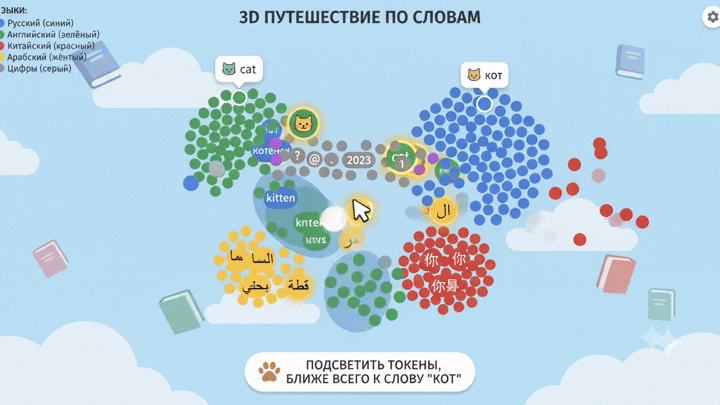
И тут становится видно глазами: редкие токены чужих языков почти всегда оказываются на границах кластеров других языков. Не потому что они туда «положены», а потому что модель не выделила им достаточно собственного пространства – их в обучении было слишком мало.
И вот этих-то «бомжей-токенов» сэмплинг и подцепляет, когда температура высокая.
Почему китайских иероглифов больше, чем арабской вязи
В практике замечают, что чаще всего пролезают именно китайские, японские и корейские символы (CJK), а не, скажем, арабские буквы. Почему?
Несколько причин:
Объём токенов. В словарях современных моделей CJK-символов гораздо больше, чем токенов других неевропейских письменностей. Просто потому что китайского текста в обучающих данных больше.
Однобайтовое представление. Многие токенизаторы (BPE, SentencePiece) разбивают редкие символы на байты. И в байтовом представлении CJK-символы часто оказываются «короче и удобнее» для модели, чем сложная вязь.
Числовая близость. Юникодные блоки CJK расположены так, что в обучении они часто соседствуют с символами пунктуации и эмодзи, которые встречаются везде. Это «приклеивает» их к универсальному ядру.
То есть когда модель сэмплирует с хвоста, в этом хвосте чаще всего лежит именно «你», «的», «是», а не «ا» или «अ».
Что с этим делать
Понимание устройства даёт прямые инструменты.
Если иероглифы лезут постоянно:
Снижайте температуру. Если у вас сейчас 0.8 – попробуйте 0.5. Если 0.5 – попробуйте 0.3. На задачах, где не нужна креативность (структурированный вывод, код, JSON), ставьте 0.0 или близко.
Используйте top-k вместо top-p, и поставьте k = 40 или меньше. Это жёстко отрезает хвост.
Добавьте repetition penalty (штраф за повтор) и logit bias – некоторые движки (llama.cpp, vLLM, text-generation-webui) позволяют принудительно занулить вероятности конкретных токенов. Можно выгрузить из токенизатора все CJK-токены и забанить их разом, если у вас задача только на русском.
Проверьте промпт. Иногда иероглифы лезут после системного промпта, который сам содержит экзотические символы (например, эмодзи или специальные юникодные пробелы) – модель цепляется за них как за «якорь» и продолжает в ту же сторону.
Если иероглифы лезут только иногда:
Это нормально для маленьких локальных моделей (7B и меньше). Их пространство сильнее «сжато», суперпозиция плотнее, интерференция сильнее.
Помогает квантование с осторожностью. Слишком агрессивное квантование (Q2, Q3) добавляет шума в эмбеддинги и усиливает эффект. Q4_K_M и выше обычно безопаснее.
Если используете LoRA или fine-tune на русском, проверьте, не убил ли вы случайно нормализацию выходного слоя. Это частая причина артефактов.
Если иероглиф появился ровно один раз и больше не повторяется:
Не паникуйте. Это статистика. При миллиардах генераций такое будет случаться.
Если для вас критично – используйте post-processing: регулярка, выкидывающая все символы вне нужных юникод-диапазонов.
Тёмная сторона: glitch-токены
Есть отдельный класс приколов – glitch-токены. Это токены, которые есть в словаре модели, но почти не встречались в обучении. Их векторы остались близко к случайной инициализации.
Самый знаменитый пример – токен «SolidGoldMagikarp» в старых моделях OpenAI. Если попросить модель повторить это слово, она начинала вести себя странно: ругалась, переключалась на другую тему, выдавала бессмыслицу. Потому что внутри это был «пустой» вектор, болтающийся в пространстве абы где.
Иероглифы в русском тексте – по сути, мягкая версия того же эффекта. Просто «вектор-сосед», который не должен был сработать, но статистически иногда срабатывает.
Сводим всё вместе
Если коротко резюмировать, почему нейросети делают так:
Текст превращается в токены, токены – в векторы.
Векторы живут в пространстве с тысячами измерений, но концептов всё равно гораздо больше – значит, работает суперпозиция, концепты накладываются друг на друга.
Из-за суперпозиции редкие токены (включая иероглифы) получают слабую активацию, когда генерируется что-то близкое по геометрии – даже если по смыслу они никак не связаны.
Сэмплинг с хвостом распределения иногда вытаскивает именно эти редкие токены.
В маленьких моделях, при высокой температуре, при агрессивном квантовании и при широком top-p – вероятность такого вытаскивания заметно растёт.
Иероглиф в русском тексте – не баг и не сбой. Это видимая верхушка айсберга под названием «как модели на самом деле хранят информацию». Под водой там – суперпозиция, фурье-структуры, grokking и геометрия, которая сложнее, чем кажется снаружи.
И когда в следующий раз модель посреди прогноза погоды выдаст вам «你», вы будете точно знать: это не она поломалась.
FAQ
Почему в больших моделях типа GPT-5 или Gemini 3 такого почти не бывает?
У больших моделей больше параметров, больше размер эмбеддинга, меньше плотность суперпозиции – редкие токены получают свои относительно изолированные направления. Плюс там стоит куча защит на уровне сэмплинга и пост-обработки. У локальной 7B-модели всего этого нет, и пространство сжато гораздо плотнее.
Связаны ли иероглифы с галлюцинациями фактов?
Механизм похожий: и то, и другое – следствие интерференции между концептами в пространстве модели. Когда вы спрашиваете про малоизвестного человека, модель «дотягивается» до соседних векторов и подсовывает биографию похожего. Просто галлюцинация фактов выглядит правдоподобно, а иероглиф – нет, поэтому первое замечают реже.
Зачем я написал эту статью?
Во-первых, мне хотелось самому глубже разобраться в теме и лучше её запомнить. По моему опыту, мысль, которую сам сформулировал и записал, усваивается эффективнее всего. Во-вторых, я просто хочу рассказать вам, чем занимаюсь в свободное время. Я изучаю LLM, тем самым подтверждая свою экспертность и демонстрируя, что действительно разбираюсь в вопросе =)